In enterprise software, few rivalries are as fascinating as Databricks vs. Snowflake. Both companies sit at the center of the modern data stack. Both sell to huge enterprises. Both are chasing the same dream: become the place where corporate data lives, moves, learns, talks, and eventually does half the work while humans pretend they “strategized.”
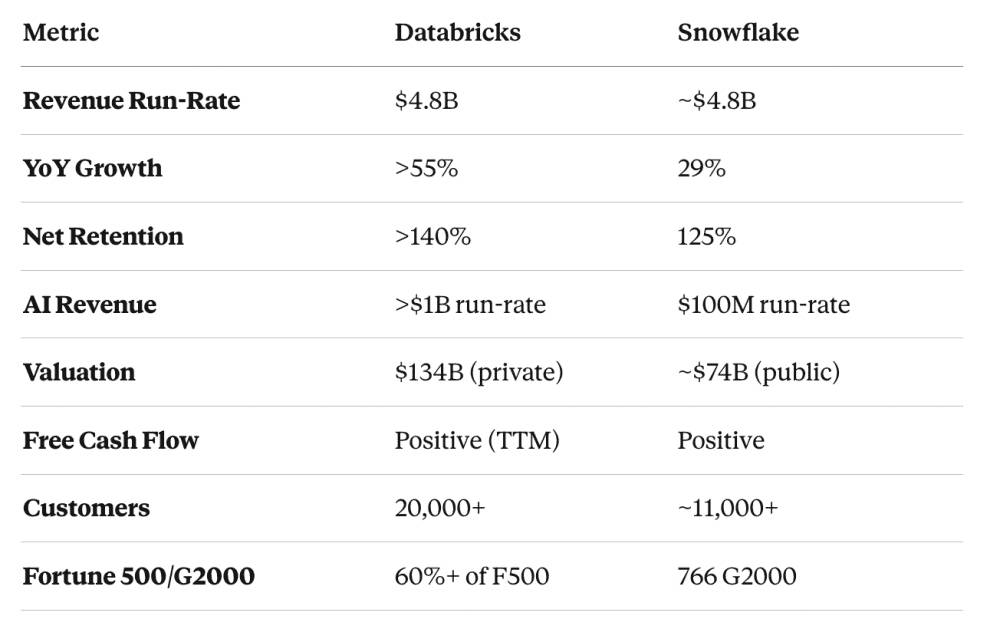
Yet the market is telling two very different stories. Databricks has crossed a revenue run-rate of roughly $5.4 billion, while Snowflake’s product revenue is now also operating in the same $5 billion-plus neighborhood. On paper, that sounds like a boxing match where both fighters weigh the same. But valuation? That is where the tale gets spicy.
Databricks was valued at about $134 billion in its latest major funding round and has reportedly discussed a new private-market raise that could value it between $165 billion and $175 billion. Snowflake, meanwhile, trades publicly at a market capitalization of roughly $80 billion. That creates the headline-grabbing question: how can two data infrastructure giants with similar revenue scale have such a wide valuation gap?
The short answer: the market is not just paying for revenue. It is paying for growth rate, AI exposure, narrative momentum, market structure, and the difference between private-market optimism and public-market discipline. The long answer is more interestingand, thankfully, less painful than reading a 200-page S-1 before breakfast.
The $5B ARR Club: Same Neighborhood, Different Speeds
At the top level, Databricks and Snowflake appear to have reached a similar revenue altitude. Snowflake reported first-quarter fiscal 2027 product revenue of about $1.33 billion, which annualizes to more than $5 billion. Its full-year product revenue guidance is even higher, at around $5.84 billion. Databricks, for its part, announced that it had surpassed a $5.4 billion revenue run-rate, growing more than 65% year over year.
That growth difference is the first major reason the valuation gap exists. Snowflake is still growing impressively for a company of its size, with product revenue up in the low-to-mid 30% range in recent results. But Databricks is growing at more than 65%, which is a very different valuation animal. Investors tend to reward faster growth with higher revenue multiples, especially when the company is tied to a massive market shift like artificial intelligence.
Think of it this way: two trains may be at the same station, but if one is moving twice as fast and headed toward “AI Infrastructure City,” investors will happily pay extra for the ticketeven if the seats are still private-market velvet and nobody has seen the full operating margin menu yet.
Why Databricks Is Getting the AI Premium
Databricks has successfully positioned itself as more than a data analytics company. It wants to be the data and AI platform for enterprises. That distinction matters. In 2026, “AI platform” is not just a product category; it is a valuation spell. Say it correctly in front of growth investors and suddenly the spreadsheet starts glowing.
Databricks’ AI product revenue run-rate has crossed roughly $1.4 billion, according to company disclosures. That is not a side quest. That is a major business line inside an already large company. The company has invested heavily in AI-native products such as Genie, a conversational analytics assistant, and Lakebase, a serverless Postgres database designed for AI agents and operational workloads.
Its acquisition strategy also reinforces the AI narrative. Databricks bought MosaicML to strengthen model training and generative AI capabilities. It acquired Tabular, founded by the original creators of Apache Iceberg, to deepen its open lakehouse strategy. It agreed to acquire Neon to add serverless Postgres infrastructure for developers and AI agents. More recently, it has pushed into cybersecurity data with Panther Labs. These moves are not random shopping-cart behavior. They point to a platform strategy: own more of the data lifecycle, from storage and governance to AI applications and agent-driven workflows.
The Lakehouse Story Still Matters
Databricks built much of its identity around the lakehouse: a model that combines the flexibility of data lakes with the structure and performance of data warehouses. That message resonated with engineering-heavy organizations that wanted open formats, scalable processing, and advanced machine learning workflows without bolting together a dozen systems like a data infrastructure Frankenstein.
The lakehouse story also gave Databricks a developer-friendly image. It is associated with Apache Spark, Delta Lake, MLflow, open-source tooling, notebooks, machine learning pipelines, and data engineering teams. That technical credibility matters in the AI era because enterprise AI is not only about dashboards. It requires messy pipelines, model features, vector search, governed data access, unstructured data processing, and production workflows. In other words, the hard stuff. The stuff that makes data engineers stare out windows dramatically.
Snowflake Is Not Standing Still
It would be a mistake to frame Snowflake as yesterday’s data warehouse wearing a “please love me, AI” sticker. Snowflake remains one of the most important companies in cloud data infrastructure. Its platform is trusted by large enterprises, its consumption model is deeply embedded, and its product revenue continues to grow at impressive scale.
Snowflake has been pushing aggressively into AI with Cortex AI, Snowflake Intelligence, Cortex Code, Snowpark, and stronger support for Apache Iceberg and open catalog strategies. The company also expanded its collaboration with AWS through a major multi-year agreement designed to accelerate enterprise AI adoption. That is not a sleepy incumbent move. That is Snowflake saying, “Yes, we also brought a sword to the AI duel.”
Snowflake’s strengths are real: ease of use, strong governance, enterprise security, cross-cloud architecture, data sharing, and a familiar SQL-first experience. Many companies love Snowflake precisely because it lowers operational burden. You do not need a room full of distributed systems experts chanting Spark configuration parameters under fluorescent lights. Snowflake made data warehousing feel manageable, and that is a powerful advantage.
But Public Markets Grade Differently
Snowflake’s challenge is not that it lacks innovation. Its challenge is that it is public. Public companies are valued under harsher lighting. Every quarter brings revenue guidance, margin expectations, stock-based compensation debates, customer growth analysis, net revenue retention scrutiny, and the occasional investor panic attack over whether AI is a tailwind or a wrecking ball.
Snowflake’s net revenue retention rate of around 126% is strong by normal software standards. But compared with Databricks’ reported retention above 140%, it looks less explosive. Snowflake’s growth is excellent for a company approaching $6 billion in product revenue, but public investors often ask, “What happens next year?” Private investors, by contrast, may ask, “What happens if this becomes the operating system for enterprise AI?” Those are very different questions, and they produce very different multiples.
The Valuation Math: Multiples Tell the Story
At a $5.4 billion revenue run-rate and a $134 billion valuation, Databricks was valued at roughly 25 times run-rate revenue. If a new private round values it around $165 billion to $175 billion, the implied multiple climbs into the low 30s. Snowflake, with a public market cap near $80 billion and revenue scale in the $5 billion-plus range, trades at a meaningfully lower revenue multiple.
That difference is the valuation gap in one clean sentence: Databricks is being valued like a hypergrowth AI infrastructure company; Snowflake is being valued like a large, public cloud software company that still has to prove AI can reaccelerate growth without hurting margins.
Is the Databricks multiple aggressive? Absolutely. Private-market valuations often bake in future dominance before all the messy evidence arrives. Is Snowflake cheap? Not exactly. It still trades at a premium compared with most software companies. But next to Databricks, Snowflake looks like the responsible older sibling with a mortgage, a calendar invite, and a reusable grocery bag.
Growth Quality: Consumption, Customers, and Expansion
Both companies benefit from usage-based revenue models. That means customers pay more as they consume more compute, storage, data processing, AI workloads, or analytics capacity. In good times, this creates beautiful expansion economics. In cautious times, it can create volatility because customers can optimize spend quickly.
Databricks reported more than 800 customers consuming at over $1 million in annual revenue run-rate and more than 70 customers consuming at over $10 million. Snowflake reported 779 customers with trailing 12-month product revenue greater than $1 million. These numbers show that both platforms are deeply embedded in large enterprises.
The difference is where investors believe incremental consumption will come from. For Databricks, the bullish case is that AI agents, model development, data engineering, and lakehouse workloads will drive a wave of new usage. For Snowflake, the bullish case is that AI will increase demand for governed enterprise data, unstructured data processing, app development, and analytics directly inside the Snowflake platform.
Both arguments are credible. But the market currently appears more willing to pay a premium for Databricks’ version of the story because it feels closer to the AI infrastructure layer that every enterprise is scrambling to build.
Open vs. Managed: A Strategic Difference
Another key difference is philosophical. Databricks leans heavily into openness: open table formats, open-source roots, interoperability, and engineering flexibility. Snowflake historically emphasized a highly managed, integrated experience: simplicity, performance, governance, and ease of adoption.
The industry is now converging somewhere in the middle. Snowflake is embracing Apache Iceberg and open catalog concepts. Databricks is working to make its platform easier and more managed for mainstream enterprise users. The old debate of “open lakehouse versus managed warehouse” is becoming less binary. Still, investor perception matters. Databricks is often seen as the platform for builders, AI teams, and technically ambitious data organizations. Snowflake is often seen as the platform for governed analytics, SQL users, and enterprise data sharing.
That perception shapes valuation because AI infrastructure buyers are still experimenting. When the future feels uncertain, investors often favor platforms that appear more flexible, extensible, and closer to developers.
Margins: The Quiet Character in the Drama
Valuation is not only about growth. It is also about how profitable that growth can become. Snowflake, as a public company, must show investors a clear path to strong margins and free cash flow. It reports product gross margin, operating margin, and free cash flow expectations regularly. That transparency is usefulbut it also gives investors more reasons to nitpick.
Databricks has reported positive free cash flow over the last 12 months, which is important. However, private companies disclose less detail than public companies. Investors may be willing to accept uncertainty because Databricks is growing faster and because AI-related infrastructure businesses are currently receiving generous benefit of the doubt.
There is a risk here. AI workloads can be expensive to serve. Compute-heavy products can pressure gross margins if not managed carefully. If Databricks eventually goes public, the market will examine its margins, customer concentration, stock-based compensation, cloud infrastructure costs, and revenue quality with a microscope powerful enough to embarrass a NASA telescope.
Private Market Optimism vs. Public Market Reality
One of the simplest explanations for the valuation gap is also one of the most important: Databricks is private, Snowflake is public. Private valuations are negotiated among a smaller group of investors. They can reflect strategic scarcity, long-term growth expectations, and the desire to own a piece of a rare asset before an IPO.
Public valuations are decided every trading day by thousands of investors who can change their minds before lunch. Public markets are liquid, emotional, and occasionally dramatic enough to deserve their own reality show. Snowflake’s stock can rise or fall based on one quarter’s guidance, macro interest-rate expectations, AI sentiment, or software-sector rotation. Databricks does not face that daily voting machine yet.
This does not mean private valuations are fake. It means they are different. A private investor may accept a higher multiple because they believe Databricks could become a once-in-a-generation enterprise platform. A public investor may hesitate to give Snowflake the same multiple until it proves sustained AI-driven acceleration under quarterly scrutiny.
Who Is Better Positioned?
The honest answer is: it depends on the workload. Databricks has a strong edge in data engineering, machine learning, lakehouse architecture, and AI-native development workflows. Snowflake has a strong edge in ease of use, enterprise governance, SQL analytics, data sharing, and managed cloud data warehousing.
Many large companies use both. This is not a winner-take-all market yet. In fact, the most realistic enterprise architecture may include Snowflake for governed analytics and data sharing, Databricks for advanced data engineering and AI workloads, and a collection of other tools that make the architecture diagram look like someone spilled alphabet soup on a whiteboard.
The real question is not “Which company wins?” It is “Which company captures the most incremental AI-driven data spend over the next five years?” That is where Databricks currently has the stronger valuation narrative. But Snowflake is fighting hard to prove that governed enterprise data is the foundation of practical AI, not merely a historical warehouse of dashboards.
Risks to the Databricks Premium
Databricks’ valuation premium is not guaranteed. High growth must eventually meet public-market expectations. If growth slows, margins disappoint, or AI product adoption proves less durable than expected, the multiple could compress quickly. Private investors may be patient, but public markets have the patience of a toddler near a cookie jar.
Databricks also faces intense competition. Snowflake is not the only rival. Cloud hyperscalers such as AWS, Microsoft Azure, and Google Cloud want more of the data and AI platform budget. Open-source ecosystems can shift quickly. Enterprises may resist platform consolidation if they fear lock-in. And as AI agents grow, data governance, security, and cost control will become even more critical.
Risks to the Snowflake Rebound
Snowflake’s risk is that it may be viewed as a cloud data warehouse first and an AI platform second, even if the product reality is evolving quickly. Investor perception can lag reality. If customers adopt Snowflake’s AI products broadly, the market may rerate the company upward. But if AI workloads move disproportionately toward Databricks, hyperscalers, or specialized vector and agent platforms, Snowflake could remain valued at a lower multiple.
Another risk is consumption optimization. Snowflake customers can manage costs by reducing usage, improving query efficiency, or shifting workloads. That is good for customer control but can create uncertainty for revenue forecasts. The company must keep proving that AI features and new workloads can more than offset optimization pressure.
The Bottom Line: Same Revenue, Different Story
The Databricks vs. Snowflake valuation gap exists because markets value stories as much as spreadsheets. Snowflake has strong revenue, major customers, improving AI momentum, and a powerful position in enterprise data. Databricks has faster growth, a more direct AI infrastructure narrative, strong expansion metrics, and private-market scarcity.
At similar revenue scale, Databricks is being rewarded for speed and possibility. Snowflake is being judged on proof and predictability. Neither approach is irrational. They simply reflect different market environments.
If Databricks goes public, the comparison will become sharper. Investors will finally see deeper financials, margins, customer metrics, and operating discipline. Until then, Databricks gets to enjoy the premium of mystery mixed with momentum. Snowflake, meanwhile, has to report every quarter under the bright lights, like a magician forced to explain the trick while still performing it.
Experience-Based Perspective: What This Rivalry Feels Like Inside Real Data Teams
From a practitioner’s perspective, the Databricks vs. Snowflake debate rarely feels as clean as investor headlines make it sound. In real companies, the choice is usually not made in a boardroom by people calmly comparing revenue multiples. It is made by data engineers, analytics leaders, finance teams, machine learning teams, security officers, and procurement managers who all want slightly different things and all believe their workload is the most important one. Naturally, everyone is correct. Also naturally, everyone is annoyed.
A typical enterprise may start with Snowflake because the analytics team needs a reliable, easy-to-use cloud data warehouse. Business users want dashboards. Finance wants governed numbers. Executives want one version of the truth, preferably one that loads before the meeting starts. Snowflake fits that pattern well. It gives teams a managed environment where SQL skills go a long way, governance is central, and performance is strong without forcing every analyst to become a distributed systems engineer.
Then the company’s data ambitions grow. The machine learning team wants feature engineering. The data engineering team wants large-scale pipelines. Product teams want event data. AI teams want to build retrieval-augmented generation systems, fine-tune models, process unstructured documents, and connect everything to agents. Suddenly, the conversation shifts toward Databricks. Its notebooks, Spark heritage, lakehouse architecture, ML tooling, and open-format approach feel natural for teams building complex data and AI systems.
In many organizations, both platforms end up coexisting. Snowflake becomes the polished, governed analytics layer. Databricks becomes the workshop where raw data is processed, machine learning models are trained, and AI experiments become production workflows. This is not always elegant. Data gets duplicated. Costs become difficult to track. Teams argue about ownership. Someone eventually creates a spreadsheet called “Platform Rationalization Final FINAL v7.” But the coexistence reflects reality: different tools solve different problems.
The valuation gap makes more sense when viewed through that lens. Databricks is getting credit for being close to where new AI workloads are born. Snowflake is getting credit for being deeply trusted where enterprise data already lives. The investor question is whether the future value pool belongs more to the builders of AI systems or the governors of enterprise data. The practical answer is probably both, but valuation markets hate saying “both” because it ruins a perfectly good debate.
For technology buyers, the lesson is simple: do not choose based on hype alone. Choose based on workload. If your priority is governed analytics, data sharing, SQL performance, and broad business adoption, Snowflake may be the cleaner starting point. If your priority is large-scale data engineering, machine learning, open lakehouse architecture, and AI application development, Databricks may feel more natural. If you are a large enterprise, you may need bothand the real challenge becomes architecture discipline, cost governance, and clear ownership.
For investors and operators, the lesson is equally clear: revenue scale is only one part of valuation. Growth rate, product direction, AI credibility, retention, margin potential, and market narrative all matter. Databricks and Snowflake may be standing near the same $5B revenue milestone, but they are being valued according to different expectations. One is priced like a private AI rocket. The other is priced like a public software giant proving it can accelerate again. Both are impressive. Only one currently gets the full AI halo.
Conclusion
The reason Databricks can command roughly twice Snowflake’s valuation despite similar revenue scale is not a single magic metric. It is a combination of faster growth, stronger AI narrative, private-market scarcity, high net retention, aggressive platform expansion, and investor belief that Databricks may become core infrastructure for enterprise AI. Snowflake remains a formidable competitor with deep enterprise trust, strong revenue, expanding AI products, and a massive customer base. But public markets demand proof quarter after quarter, while private markets can pay today for what they believe tomorrow will look like.
In the end, the Databricks vs. Snowflake battle is not just about data warehousing or lakehouses. It is about who owns the enterprise data operating layer in the AI era. Snowflake wants governed data to become the foundation for intelligent business applications. Databricks wants the lakehouse to become the platform where data, models, apps, and agents converge. Same revenue neighborhood. Different growth profile. Different market structure. Different story. And in software valuations, the story can be worth tens of billions.
Note: Valuation, revenue run-rate, market capitalization, and growth figures can change quickly, especially for private companies and public software stocks. Before publishing, verify the latest financial disclosures and market data to ensure accuracy.